The CMDB of the Future
OnApplication Monitoring, Developer's Corner
 (NOTE: This post appeared in the January 13 issue of APMdigest)
(NOTE: This post appeared in the January 13 issue of APMdigest)
The complex software applications that run modern businesses are often referred to as “mission-critical” and must be kept running 24×7. Unfortunately, the complexity of these applications is often so great that keeping them in a healthy state can be challenging, to say the least.
The Configuration Management Database, or CMDB, was conceived a few years back as a way to discover and maintain a repository of all components on which an application is dependent, along with information about their relationships. Apart from its use in asset management, the thought was that combining the CMDB with real-time monitoring metrics obtained from the underlying components could provide insight into the health state of complex applications, with early warning of incipient problems, and guidance to root cause when incidents do occur.
This is a powerful vision with potentially far-reaching benefits. It is a bit like the internal monitoring system in a modern automobile which relies on a complete and well-defined database of all the components on which the vehicle’s operation is dependent and how a failure of any one component might affect the mission-critical operation of the vehicle. A soft female voice might warn you, for example, that your tire pressure is low … and she didn’t have to “learn” that low tire pressure can cause a blowout by having one first.
Similarly, today’s large, complex, mission-critical business applications can have a huge number of moving parts and underlying software components … with lots of things that can go wrong. Is it possible to identify and maintain a database of all the internal dependencies of a complex application and create a warning system like that in a modern automobile that is highly deterministic and reliable and can prevent incidents from ever happening in the first place ?
Sounds like a really great idea … why then, has the CMDB seen only limited adoption and little commercial success ?
Weaknesses of Conventional Configuration Management Tools
We have seen many products in recent years designed to create and maintain such a Configuration Management Database. However, practical challenges have prevented this vision from becoming reality, and the CMDB seems to have lost favor as a realistic contributor to a monitoring solution. While successful to some extent, the general consensus seems to be that these products have been simply too limited in functionality or too difficult to use for maintaining reliable content. For some detailed criticism, see “IT Skeptic” Rob England’s blog CMDB: What Does It Really Mean ?
Monitoring a complex multi-tiered application involves the collection of data from many different sources, including infrastructure data (host cpu and memory), middleware service data (message flows, session counts), and application data like log file content or data exposed through JMX. Typically, this can include a dozen or more specific types of data for any platform you build.
Using a traditional CMDB or service model a user would either 1) manually define the dependency relationships between these components and each application that uses them, or 2) use a tool to auto-discover the relationships using some form of heuristic algorithm. Both of these methods have serious drawbacks. It is impractical to manually maintain a service model when components are continually being added or the system is modified. The heuristic method seems promising but the drawbacks are just as severe although more subtle; minor flaws and inaccuracies constantly plague the system and can cause mysterious errors that go undetected for a long time.
Automobile manufacturers gradually figured out how to manage the information needed to effectively maintain the health and safety of a moving vehicle. In a similar way, developers of complex applications are slowly discovering ways to make monitoring these systems more automatic and reliable. Fundamental changes in the IT landscape are helping as well.
Automating SOME of the Service Model Definition
The first step in making any system more automatic (and thus more reliable) is to dramatically reduce the amount of manual maintenance required. It is also essential that the methodology is deterministic and not heuristic (and prone to subtle errors). Let’s use a concrete example to explore ways this can be done.
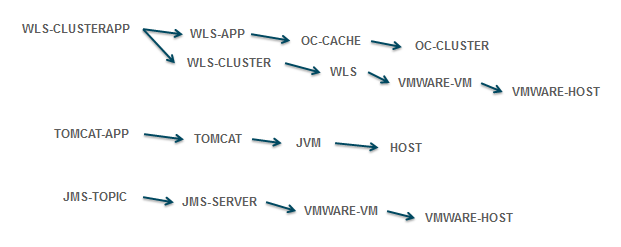
Consider a Java application that is built on a standard message-oriented integration platform. The application itself might be dependent on a JMS server and a few specific message queues, as well as an Oracle database, a Tomcat server, and several JVMs, all running on a couple of VMWARE Virtual Machines (VMs).
 Using a strictly manual approach, one would list each individual component on which the application is dependent, and in doing so build the service model or CMDB table.
Using a strictly manual approach, one would list each individual component on which the application is dependent, and in doing so build the service model or CMDB table.
However, we can be smarter and automate much of the CMDB definition process if we take advantage of known dependencies between data types, as shown in the diagram to the right. For example, a TOMCAT-APP runs within a TOMCAT server which is a JVM that runs on a specific HOST. Similar logic could be applied to JMS Topics, WebLogic Applications, and many other component types.
By applying these rules, it is possible to specify just the name of the JMS-TOPIC and the URL of the TOMCAT-APP, and all the related components of the application can be derived automatically. With just two entries in the CMDB it is possible to deterministically describe the service model for this application … and subsequently aggregate the important metrics for each component to calculate and present a measure of the health state of that application, as well as alert on exceptional conditions.
This technique can be even more effective if the identifier for each top-level component can be readily associated with the application that uses it. For example, if a queue associated with the “Inventory” application is named INVENTORY.QUEUE.1 and the one used by “Order Processing” is ORDERS.QUEUE.1, it is easy to parse the names and automatically populate the CMDB service model with the proper dependencies as well as dynamically update it with zero manual intervention.
In working with dozens of larger organizations, SL Corporation has seen greater adoption of these techniques and best practices to achieve more reliability and automation in monitoring critical applications. But there is big change in the IT landscape that influences CMDB evolution in an entirely different way.
Automating ALL of the Service Model Definition
The introduction of virtualization technology has spawned a significant revolution in computing, somewhat akin to the transition from discrete semiconductor components of the 1950s to the era of fully integrated circuits. What used to take hundreds of individual components wired together on a circuit board could now be embedded in a single chip and stamped out in huge volumes. The integrated circuits of today routinely contain tens or hundreds of thousands of components on a single chip.
Though still in the early stages, something similar has happened with virtualization and software as a service. In an instant you can provision a virtual machine with a complete operating system of your choice (Infrastructure as a Service). You can also include middleware components like a full-featured Application Server (Platform as a Service). With custom application software, we are not as far along … you still need to wire lots of virtualized components together to make a complex integrated application.
It is easy to see the obvious benefits of virtualization for providing fast and cheaper access to computing power. But not everyone recognizes that there is a more subtle, yet powerful, force at work here … one that can significantly enhance the ability to automate and make deterministic the monitoring of the health state of complex applications. It used to be that IT would order hardware and after it arrived would manually configure the operating system and other platform software required by application developers. Not so any more.
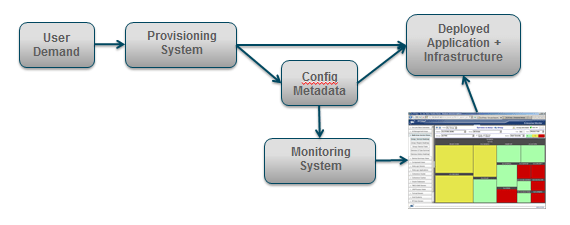 With virtualization, the provisioning of a new “platform” is completely data-driven. This means that configuration information about the physical location, IP address, service names and ports for all components is maintained in a file or database table (referred to as metadata) and is used to deploy the requested components.
With virtualization, the provisioning of a new “platform” is completely data-driven. This means that configuration information about the physical location, IP address, service names and ports for all components is maintained in a file or database table (referred to as metadata) and is used to deploy the requested components.
This deployment metadata can do “double duty” and be used to configure a comprehensive monitoring solution to accompany each application. Ideally, every component of a complex application, from infrastructure to middleware to custom processes, and all their interdependencies will be identified in the metadata, providing precisely the functionality that has eluded developers of the current generation of CMDB.
Eventually, this “CMDB of the Future” will be one and the same as the deployment metadata used in provisioning systems. At a minimum it would be generated automatically. There is already a well-known CMDB data definition consisting of a repository of Configuration Items (CIs) and the relationships between them. Up to now it has been difficult to construct a dependable CMDB, whether manually or heuristically. However, by automatically deriving it from provisioning metadata, we could finally see emerge a completely deterministic and reliable CMDB used to map the health state of underlying components to the business services that are dependent on them.
Clearly, we are quite a ways from this goal … but progress may be just ahead. Sometimes the most significant advances are not the latest and greatest that you read about in the trade press but instead are the ones going on quietly behind the scenes and without a lot of fanfare. I suspect that the next generation Configuration Management Database may be just such a thing.
In this post, I’ve barely touched on this very rich and deep subject area. More to come. In the meantime, you can find a lot of interesting materials on the SL Web Site, and especially in some of our other blogs. I wouldn’t be writing about all this if I didn’t think the RTView product had what it takes to address these issues. I recently did a webinar entitled Shortfalls in Monitoring Virtualized Apps. It is only about 30 minutes long and touches on this subject in a little more depth. You might want to check it out.
Categories: Application Monitoring
Developer's Corner