In his recent post in The Virtualization Practice, Bernd Harzog hits the nail on the head with Real-Time Monitoring: Almost Always a Lie. Here, Bernd points out that, in contrast to marketing claims that a monitoring solution is real-time, the fact is that multiple stages of data collection, processing and distribution introduce significant delays that dramatically limit how current monitoring data can actually be. Cumulatively, this delay can be quite large.
In his recent post in The Virtualization Practice, Bernd Harzog hits the nail on the head with Real-Time Monitoring: Almost Always a Lie. Here, Bernd points out that, in contrast to marketing claims that a monitoring solution is real-time, the fact is that multiple stages of data collection, processing and distribution introduce significant delays that dramatically limit how current monitoring data can actually be. Cumulatively, this delay can be quite large.
Consequently, all monitoring solutions are not truly “real-time.” In fact most struggle to be even “near” real-time. The question is how near do you need to be … or want to be ? And how can you get there ?
History offers some perspective. By 1773, the British Parliament had awarded John Harrison $4,000,000 (today’s equivalent) for his life’s work in developing a sea-worthy chronometer capable of keeping time to an accuracy of five seconds over a journey of several months. This was deemed sufficient to solving a big problem back then… precisely determining a ship’s longitude in order to avoid crashing on rocks when returning home. We’ve come a long way since then and now have atomic clocks that are accurate to femtoseconds (a millionth of a billionth of a second).
Today’s problem is more about how to avoid crashing your critical business applications on errors such as Out-Of-Memory, Max-Queue-Size-Exceeded, or Too-Many-Users. It would be a huge benefit if one could instantaneously determine that these conditions were imminent and automatically initiate actions to throttle activity or purge the offending queue, eliminating any possibility of a crash. Unfortunately, the technical challenges to instantaneous real-time are substantial, and we have to live with however near we can get to real-time.
Ten years ago, typical System Management Software would collect data every 5 or 15 minutes (and many still do). Today, a monitoring system that can collect, process, and report on data every 10 or 15 seconds would be considered real-time, relatively speaking. Most do not even do that. In some cases it is possible to collect data faster, but it can be difficult to generalize this to all monitoring data.
In his post, Bernd makes the recommendation that one must carefully limit the data collected in near real-time, otherwise a large Big Data System will be needed to process it. This is helpful to a degree, but in monitoring large scale distributed applications, big data volumes are inescapable. It is essential that techniques be developed to maximize what we can monitor. How can we get as close as possible to real-time with as much important data as possible ? In working with monitoring data of all kinds for the last 25 years, SL Corporation has uncovered a few of these techniques.
Eliminate the Central Bottleneck
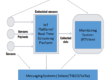
The first step in getting closer to real-time is to eliminate the bottleneck that is inherent in any system that manages data centrally. It is impossible to get anything close to real-time if all data in the application need to be sent to a central server and written to a central database. Instead, leave the data in servers that reside close to the source. In other words, distribute the load. Collect the data in remote locations and leave it there, but make it available through standardized queries to those who need it. Yes, there will be some latency when data are requested, but you eliminate the more significant latency inherent in concurrently transferring all data to a central location.
Perform Local Aggregation and Analysis
Applications often use infrastructure resources in parallel. For example, several WebLogic servers may act together to implement load-balancing of a particular service. If one can identify the most common of these aggregations, the processing can be performed out in the data servers local to the source of the data, eliminating the need to transfer the raw data and aggregate it centrally. The results of these aggregations can be maintained in the data server as just another data set, visible to any user who needs to access them. Of course, not all groupings can be identified up front, but many are commonly used and well-defined. This approach can dramatically reduce the volume of data and hence the latency inherent in a monitoring system.
Transmit Only Data That Have Changed
If one has to query (or transfer) a complete data set on a regular basis, there is an inherent limitation to how current any one data item can be. A lot of monitoring data will not change that rapidly. For example, the session count on an individual App Server won’t change until someone logs in or out. If, instead of batching the entire data set, individual rows of data are transferred as soon as they have changed, the interval between the time a row changes and the time it is seen by a user can be much shorter. This, of course, requires a caching architecture that supports indexed insertions and extractions, something not often seen in commodity monitoring systems.
To create a watch that was accurate to 5 seconds, many years had to be invested in developing all sorts of tiny parts to compensate for temperature changes, a ship’s up and down motion, and many other challenges. Similarly, in developing a (near) real-time monitoring solution, there are many optimization techniques and algorithms that need to be created and perfected over a period of time.
Perhaps, many years from now, monitoring systems will be collecting data and performing automated actions within femtoseconds. But for now, like John Harrison back in 1750, we are plugging away trying to figure out how to make our systems a few seconds faster this year than they were last year.