I continue to be impressed by the success of TIBCO’s BusinessWorks (BW) integration platform in large-scale banking, e-commerce, logistics, and insurance applications. Enterprise developers combine BW with TIBCO Enterprise Messaging System (EMS) to create their largest and most important customer facing applications — also known as “big money apps”.
I continue to be impressed by the success of TIBCO’s BusinessWorks (BW) integration platform in large-scale banking, e-commerce, logistics, and insurance applications. Enterprise developers combine BW with TIBCO Enterprise Messaging System (EMS) to create their largest and most important customer facing applications — also known as “big money apps”.
BW’s continued momentum comes from its ability to orchestrate complex sequences of user interactions with back-end systems, such as databases, ERP and CRM systems, and even custom applications. But its success has also resulted in a significant amount of software sprawl. A large enterprise can have hundreds or thousands of BW engines, EMS servers, custom adapters and orchestration processes — a labyrinth of software components on which critical business services are implemented.
Complexity is a Given
Most IT executives and architects have long experience in dealing with complexity. You routinely pay top dollar for IT and middleware specialists to keep the servers running, identify overloaded queues, and perform other highly technical, day-to-day firefighting. But “IT leadership”, as we will discuss here, is often in the dark about the real state of those systems and the potential hazards hiding in the complexity. The rate of change is accelerating and there is an increased onus on IT to industrialize its response to this complexity.
From the point of view of the CIO or other IT executive in a large organization, a big challenge in managing these systems has to do with managing people — the highly paid specialists who know all the technical details and whose work is so critical to a smooth operation. They don’t always agree on what is happening in the system. A second challenge is determining whether all hardware and software assets are being utilized efficiently, and whether the huge investment made in IT resources is really worth it.
Challenge #1 — Who Ya Gonna Call ?
 For a modern high-level IT director, the first challenge is captured nicely in the old Ghostbusters lyric, “If there’s something strange in your neighborhood, who ya gonna call?”. When something goes wrong in a big complex application, there are usually several different groups who might be involved, each responsible for a different subsystem. It can be hard to know who to call.
For a modern high-level IT director, the first challenge is captured nicely in the old Ghostbusters lyric, “If there’s something strange in your neighborhood, who ya gonna call?”. When something goes wrong in a big complex application, there are usually several different groups who might be involved, each responsible for a different subsystem. It can be hard to know who to call.
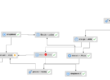
In large applications built around BusinessWorks and the rest of the TIBCO stack, the typical subsystems can include: infrastructure (hardware/network/OS), messaging (EMS), orchestration (BW), and applications (business services). Each team will have their own monitoring tools to troubleshoot their particular area. But that is the problem — they are the only ones who have access to or know how to use those tools. The information they have is not available to anyone else, leaving management powerless and completely at the mercy of technical specialists.
What happens when the pressure is on and management has little or no visibility into which subsystem might be causing trouble? There is only one possible option — call everyone! And convene yet another “war room”, with all the finger pointing, frantic digging for data, and concomitant waste of time and money.
Knowing Who To Call — and How To Make Them Effective
Fortunately, there is a solution. Experienced IT Directors know that giving their people yet another APM or low-level transaction monitoring tool isn’t going to help. Something dramatically different is needed — and here is what it should look like.
Provide IT Leadership Meaningful Visibility. Critical information about the health state of all underlying subsystems needs to be surfaced and made available to management and to other departments at all times. But it cannot be just “raw data”. The data need to be summarized and organized in ways that will enable management to quickly determine which subsystem is affected so that all groups don’t need to be called into a war room. You can read more about this in What Failed: My App Or My Infrastructure?.
All The Data — Right Now. Especially during major outages, it is essential to have “at your fingertips” all available data about critical components, up and down the entire stack. Without it, a tremendous amount of time can be wasted searching through logs or the TIBCO Administrator to find the needed data, often scattered across many different components.
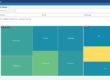
Heterogeneous Diagnostics. All the data need to be collected from the TIBCO components as well as non-TIBCO components. All data about every EMS server, queue, BW engine, process, activity, Adapter engine, Business Events and Active Spaces components may need to be available at any time. You can’t have your people going to four different tools to find the data they need and they can’t be looking at “one server at a time”. The data need be aggregated in ways that make sense, showing total metrics and breakdown across all servers in a load-balanced cluster, for example.
Scalable Data Model. Diagnosing big money apps can generate tons of data, so the wrong data model can cost you dearly. Some products attempt to solve this by transferring all data to a central server for storage and presentation. In most cases, it is simply not practical to collect in real-time large volumes of data centrally. A system is needed that can efficiently summarize and access large amounts of data “in-place”, minimizing load on what is likely an already stressed network.
Challenge #2 — Is All Of This Investment Worth It ?
Big money gets spent keeping these business-critical applications up and running 24×7 and performing well. But how do you know if the money is being spent wisely — if all those servers and software licenses are being utilized effectively?
Capacity and Utilization. Application Monitoring isn’t just about validating that your servers are running or the applications are processing data. The technical specialists can usually figure that out. The bigger issue is determining whether the capacity of the infrastructure that is currently in place is enough to handle the extra load that occurs on days like Black Friday or Dec 26th, or any number of special events. Or maybe there is way too much capacity and financial resources are being wasted unnecessarily.
Historical Context. Every organization needs to look back and see what happened in their systems yesterday, last week, or last year at the same time. This is needed for high-level directors to understand the rate at which capacity utilization of their systems is growing, and if and when additional investment in IT may be justified.
For over ten years, SL Corporation has worked with hundreds of TIBCO customers who use BW and EMS in large complex business-critical applications. Most of them have used SL’s RTView monitoring product to keep track of the overall health state of those systems as well their levels of utilization. As a result we have been exposed to just about every architectural variation and problem incarnation possible. And in doing, the RTView product has evolved year over year to provide comprehensive solutions to the many of the challenges described above.
I published several blogs recently which are particularly relevant to monitoring and management of large TIBCO-centric applications. They can provide a lot of additional information and detail about how RTView addresses these issues.
Advanced TIBCO Monitoring with RTView
RTView for TIBCO – More Than APM
Additionally, the blogs listed below provide some color on how RTView addresses the challenges inherent in dealing with large volumes of real-time monitoring data.
How Real-Time Do You Want To Be?”
Big Data – Not Just An Amorphous Blob
by on 02/02/2015