Business Value: A Nice To Have ?
OnApplication Monitoring, End to End Monitoring
With every new year, we see a flood of research notes, articles and blog posts regarding the latest IT strategic priorities. This year, these priorities range from analytics, to single transaction platforms, to cloud and mobile strategies, etc. However, it is rare to see a list that includes, as a top priority, improvements to the monitoring of critical systems.
As “big money” applications grow more complex and data volumes grow exponentially, we see outage after outage that could have been avoided with improved visibility into their overall health state. So why doesn’t monitoring make the cut? Is it really OK to “limp along” with in-house custom scripts and existing siloed component-level monitoring tools, and make further investment in monitoring a “nice-to-have?”
Not if you ask the managers of IT Departments and App Support teams. For them, monitoring these systems is much higher on the priority list. Why? Because they need to cut costs, reduce headcount, become more efficient, reduce downtime, and so on. They need to do more with less. They also need to have their teams focus on developing new applications, rather than constantly getting dragged into triage of problems with the ones they already have. They will excitedly tell you that they “have-to-have” these things.
Clearly, there is a disconnect here – a bit like not seeing the forest for the trees. The “trees” are the day-to-day problems and outages that demand constant attention. Traditional monitoring tools that expose data one server at a time, or are siloed around specific technologies just make the problem worse. It is difficult for overwhelmed IT managers and application support teams to see that the real problem is NOT the outage of the day – but rather the enormous waste of time and resources that results from inefficient processes, poor communication between teams, and lack of real-time visibility into system health state.
I wrote another blog recently, Enterprise Application Monitoring: The Business Value. In it, I show how orders-of-magnitude more business value can be achieved by focusing on the communication and management of monitoring data across the enterprise (the forest). Providing real-time status of critical systems to the people who can effectively use it can result in avoidance of problems in the first place, rather than troubleshooting them afterwards (the trees) !
Let’s look at a common and concrete example – a middleware team responsible for managing the messaging servers that enable application integration across an enterprise. Other groups across the organization develop and manage critical applications that make heavy use of this central messaging service, creating message queues that go up and down in length as the applications execute.
We see two big problems surface in almost every instance of this:
1) The middleware group can monitor these queues, but they have absolutely no idea whether the length of any particular queue is good or bad or might be causing issues in an application.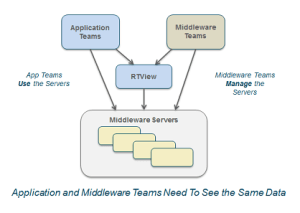
2) The application developers (who know about the queues) are typically not provided access to the monitoring data that tells them there may be a problem brewing – they are flying blind.
So what happens? An application eventually crashes, and the middleware people and application people get together in a war room and scramble to figure out what went wrong, while management hovers over them to fix the outage before more revenue is lost.
This scenario can easily be avoided by providing the application support group with detailed information about the state of all their queues (as well as data about other important infrastructure components). If they could see for themselves what was happening with the underlying services and components on which their apps depend, they would have complete control to start and stop or throttle processes as needed to head off an outage at the source. Providing the app support teams with such visibility and control would free the middleware teams to focus on higher priorities.
This is huge. By investing in effective end-to-end monitoring, companies are both reducing outages AND reducing costs. It is exactly what RTView is designed to provide. Yes, there are some really advanced data collection, analysis, and visualization capabilities that are provided with RTView. However, it is this ability to provide access to critical health state information to the people who can really use it that makes such a huge difference in avoiding outages in the first place, and keeping everyone focused on how they can best impact the bottom line.
Categories: Application Monitoring
End to End Monitoring