Analytics on RTView Data Using R
OnDeveloper's Corner
![]() “R” has become the tool of choice for data scientists around the world for a variety of reasons. First, the language simply and powerfully expresses vector and matrix operations so you can interactively manipulate and explore your data from the command line. If you find yourself doing the same sequence of operations over and over, it’s easy to package them as a re-usable function and further enhance interactivity. Like Perl, R is backed by a large collection of add-on packages maintained in CRAN, the “Comprehensive R Archive Network”. Finally, R is great for repetitive scripted batch processing.
“R” has become the tool of choice for data scientists around the world for a variety of reasons. First, the language simply and powerfully expresses vector and matrix operations so you can interactively manipulate and explore your data from the command line. If you find yourself doing the same sequence of operations over and over, it’s easy to package them as a re-usable function and further enhance interactivity. Like Perl, R is backed by a large collection of add-on packages maintained in CRAN, the “Comprehensive R Archive Network”. Finally, R is great for repetitive scripted batch processing.
In this article, we’ll learn how R can be used to interactively explore relationships in data from your RTView repositories, and provide views that complement those available in RTView Enterprise Monitor. This will be a gentle introduction to R, with no prior experience assumed. For those wanting a firmer foothold, I recommend “Impatient R“, a quick and fun read by Patrick Burns, as well as the many excellent MOOC’s at Coursera, edx, Stanford, and elsewhere. You might also print out the “R Reference Card“.
To follow the steps in this article, you’ll need to download R. Installation is a snap; just accept all the defaults if you’re not sure. For more advanced work in R, you should also install R-Studio (free desktop version). In this article, we’ll use the simple RGui that is part of the baseline R installation. For Windows, installation will have put some R icons on your desktop. Let’s click the 32-bit icon and get started!
Using the R Console
First, we’ll provide a bit of orientation (just enough for the rest of the article to make sense). The R command-line is expression-oriented, so typing an expression into the RGui console window with variables and functions will print a result and then prompt (“>”) for the next entry. However, when you use the assignment operator “<-“, nothing is printed. For example, the following lines show an assignment to x, and then use the expression “x” to list its current value.
> 2+3
[1] 5
> x <- 2+3
> x
[1] 5
>
At this point, you might be puzzled by the result “[1] 5”. Well, R treats scalars as vectors of length 1. This can be seen in the following lines, where the shorthand “1:n” means generate a sequence (vector) of numbers from 1 to n. The number in brackets is the index into the vector of the next number printed.
> 1:20
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
[17] 17 18 19 20
> x <- 1:5
> length(x)
[1] 5
> y <- 6:10
> x+y
[1] 7 9 11 13 15
> c(1,2,7,9) # "concat" the elements 1, 2, 7, and 9 to create a vector
[1] 1 2 7 9
>
Note that the “+” operation on the vectors x and y creates a new vector that is the pair-wise sum of x and y. Simple expressions on data structures is what makes R so powerful. Besides vectors, R supports matrices, arrays, and dataframes. For interactions involving RTView data, vectors, matrices, and arrays have a serious limitation; their elements must be of the same type (numeric, integer, complex, logical, or character). Dataframes, on the other hand, can have columns of any type, and can therefore better handle the data stored in RTView caches. But before moving on to the real meat of this article, I’ll list a few “must know” functions that will be useful. To get more information on these or others, use “?name” or help(“name”) at the command prompt. Also, apropos(“set”) will list the names of functions that contain the substring “set” in their name.
| Function | Description |
|---|---|
| getwd() | returns the filepath of the current working directory for the R process |
| setwd(“path”) | sets the current working directory |
| dir() | list the files in the current working directory |
| head(dataframe) | returns the first n rows of a dataframe |
| ls() | lists the objects defined in the current environment |
| source(“filepath”) | parse the given file with R code and add its content to the current environment |
| read.delim(“url”) | read a file from a web server with tab separated values and return a dataframe |
| str(object) | describes the structure of an R data object |
| fix(dataframe) | launches an editor so you can easily view and/or change the values of cells in your dataframe |
Working with RTView Current Data
Now that we have a feel for the R command-line, let’s put it to use! First, we’ll query RTView using the REST interface for current data in the HostStats cache.
> hosts <- read.delim("http://rtvserver/bwmon_rtvquery/cache/HostStats/current?fmt=text")
> dim(hosts)
[1] 4 30
> names(hosts)
[1] "time_stamp" "domain" "hostname" "OS_Name"
[5] "OS_Description" "OS_Version" "Uptime" "CPU_Model"
[9] "numCPUs" "loadAvg1" "loadAvg5" "loadAvg15"
[13] "MemTotal" "MemUsed" "MemFree" "MemUsedPerCent"
[17] "VMemTotal" "VMemUsed" "VMemUsedPerCent" "swapTotal"
[21] "swapUsed" "swapUsedPerCent" "userPerCentCpu" "systemPerCentCpu"
[25] "idlePerCentCpu" "usedPerCentCpu" "agentType" "agentClass"
[29] "source" "Expired"
>
So, the hosts dataframe has 4 rows and 30 columns. The “names” function gives us a list of the column names. When there are a lot of columns, it becomes messy trying to print and examine your dataframe. Using subscripts, we can print subsets of large dataframes.
> hosts[1,1]
[1] Jan 27, 2015 8:41:22 AM
4 Levels: Jan 27, 2015 8:41:20 AM Jan 27, 2015 8:41:22 AM ... Jan 27, 2015 8:41:37 AM
The cell in the first column and row of this dataframe is definitely a timestamp. (The “4 Levels” bit will become clear after the next command.) We can also use vectors as indices to subset and explore bigger chunks data. For example, hosts[1:4,c(3:5,9)] prints the first 4 rows, with third thru fifth plus the ninth columns. But, instead of shooting in the dark, we could more intelligently work with this data if we knew more about its structure. R provides the “str” function for just this purpose!
> str(hosts)
'data.frame': 4 obs. of 30 variables:
$ time_stamp : Factor w/ 4 levels "Jan 19, 2015 2:24:03 PM",..: 2 3 4 1
$ domain : Factor w/ 1 level "myHawkDomain": 1 1 1 1
$ hostname : Factor w/ 4 levels "slel4-64(slmon)",..: 4 3 1 2
$ OS_Name : Factor w/ 3 levels "Linux","Unix",..: 1 2 1 3
$ OS_Description : Factor w/ 3 levels "HP-UX","Linux",..: 2 1 2 3
$ OS_Version : Factor w/ 4 levels "2.6.18-8.el5",..: 1 4 2 3
$ Uptime : int 5295748 1224240 5293946 51796
$ CPU_Model : Factor w/ 4 levels "amd64","i386",..: 2 3 1 4
$ numCPUs : int 1 2 2 2
$ loadAvg1 : num 0.03 0.0142 2.11 -1
$ loadAvg5 : Factor w/ 4 levels "-1.0","0.013986291167833866",..: 3 2 4 1
$ loadAvg15 : Factor w/ 4 levels "-1.0","0.0","0.013083335749972134",..: 2 3 4 1
$ MemTotal : num 1011 20469 1001 3072
$ MemUsed : num 995 19949 989 2161
$ MemFree : num 0 0 0 0
$ MemUsedPerCent : num 98.4 97.5 98.8 70.3
$ VMemTotal : num 2994 40937 2728 4932
$ VMemUsed : num 1311 22432 2154 1378
$ VMemUsedPerCent : num 43.8 54.8 79 27.9
$ swapTotal : num 0 0 0 0
$ swapUsed : num 0 0 0 0
$ swapUsedPerCent : num 0 0 0 0
$ userPerCentCpu : Factor w/ 4 levels "0.0","0.5","1.1979166666666652",..: 1 2 4 3
$ systemPerCentCpu: num 0 0 35 -1
$ idlePerCentCpu : Factor w/ 4 levels "100.0","50.5",..: 1 4 2 3
$ usedPerCentCpu : Factor w/ 4 levels "0.0","0.5","1.1979166666666714",..: 1 2 4 3
$ agentType : Factor w/ 1 level "Hawk": 1 1 1 1
$ agentClass : Factor w/ 2 levels "TIBCO Hawk Agent-4.8.1_V7",..: 2 1 1 1
$ source : Factor w/ 4 levels "slel4-64","slhost6",..: 4 3 1 2
$ Expired : Factor w/ 1 level "false": 1 1 1 1
>
We see that several of the columns appear to be factors (ie, similar to “enumerated types” in programming languages). Let’s examine the load averages for our linux/unix hosts (this value is not available for Windows hosts, so this cell has a value of -1). First, we’ll subset the dataframe to eliminate Windows hosts using the “OS_Name” factor, then get statistics for the one minute load average. The following line essentially means “give me the hostname and loadAvg1 columns for rows where OS_Name is not Win32”.
> unixhosts <- hosts[hosts$OS_Name != "Win32",c("hostname","loadAvg1")]
> unixhosts
hostname loadAvg1
1 slvmrh2(slapm) 0.0300000
2 slhpux11(slmon) 0.0142274
3 slel4-64(slmon) 2.1100000
> mean(unixhosts[,2])
[1] 0.7180758
> min(unixhosts[,2])
[1] 0.0142274
> max(unixhosts[,2])
[1] 2.11
> quantile(unixhosts[,2])
0% 25% 50% 75% 100%
0.0142274 0.0221137 0.0300000 1.0700000 2.1100000
> summary(unixhosts$loadAvg1)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.01423 0.02211 0.03000 0.71810 1.07000 2.11000
>
Note that the loadAvg1 column of unixhosts was extracted by using “[,2]”. We could have obtained the same result using [,”loadAvg1″], or even better unixhosts$loadAvg1. Leaving the rowset unspecified means to include all rows. Finally, when you need to select a set of columns, use a list of either column names or column numbers.
> hosts[,c(3,4,10,14,23)]
hostname OS_Name loadAvg1 MemUsed userPerCentCpu
1 slvmrh2(slapm) Linux 0.0300000 995.0469 0.0
2 slhpux11(slmon) Unix 0.0142274 19948.5625 0.5
3 slel4-64(slmon) Linux 2.1100000 988.6953 14.5
4 SLHOST6(domain6) Win32 -1.0000000 2160.9727 1.1979166666666652
>
Of course, if we had wanted fewer columns to begin with, we could have narrowed the original RtView REST query by adding a column clause.
> hosts2 <- read.delim("http://rtvserver/bwmon_rtvquery/cache/HostStats/current?fmt=text&cols=hostname;OS_Name;loadAvg1")
> names(hosts2)
[1] "hostname" "OS_Name" "loadAvg1"
>
Split – Apply – Combine
Although R offers conventional programming constructs like loops, the “R way” of interactively manipulating data avoids these where possible. A common example is reducing a dataframe to just the rows and columns needed for a given computation. The split function splits a dataframe by a factor and returns a list of dataframes indexed by the factor values, while the “lapply” and “sapply” functions process each element in a list, and combine the results. “tapply” can often do both jobs, without the need to explicitly split the data.
The following example starts by converting the userPerCentCpu from a factor to an ordinary numeric column (which is sometimes necessary when R inappropriately thinks a column is a factor), then splits the dataframe by OS type, and computes the average CPU utilization across all the hosts for each OS. The sapply function applies an anonymous function which applies the mean to the third column, and then summarizes the result into a compact vector. The tapply example counts all the hosts by OS type. Finally, the attach function can reduce the amount of typing required by providing context. The second use of tapply produces the same results, but without the need to prefix the column vectors with “hosts$”.
> hosts[,23] = as.numeric(as.character(hosts[,23]))
> hostlist <- split(hosts[,c(3,4,23)],hosts$OS_Name)
> hostlist$Linux
hostname OS_Name userPerCentCpu
1 slvmrh2(slapm) Linux 0
4 slel4-64(slmon) Linux 74
> sapply(hostlist,function(x) mean(x[,3]))
Linux Unix Win32
37.000000 1.000000 2.122746
> tapply(hosts$OS_Name,hosts$OS_Name,length)
Linux Unix Win32
2 1 1
> attach(hosts)
> tapply(OS_Name,OS_Name,length)
Linux Unix Win32
2 1 1
>
Histograms
RTView Enterprise Monitor provides heat maps for visualizing status of various metrics for a large number of resources. This visualization technique subsets valuable screen real estate and can become quite dense as the number of resources “N” increases. Histograms don’t have this limitation, so we can concisely show load for thousands of hosts. First, we’ll pull in current data for some virtual machines managed by our vSphere server, then show CPU utilization in a histogram.
vmw <- read.delim(“http://localhost:8068/vmwmon_rtvquery/cache/VmwVirtualMachines/current?fmt=text”)
> dim(vmw)
[1] 26 20
> names(vmw)
[1] “time_stamp” “connName” “name”
[4] “hostname” “managedObjectId” “cpu.usage.average”
[7] “disk.read.average” “disk.write.average” “mem.active.average”
[10] “mem.swapped.average” “mem.usage.average” “net.received.average”
[13] “net.transmitted.average” “net.packetsRx.summation” “net.packetsTx.summation”
[16] “net.droppedRx.summation” “net.droppedTx.summation” “rxPacketsDroppedPercent”
[19] “txPacketsDroppedPercent” “Expired”
> hist(vmw$cpu.usage.average,breaks=20)

Using RTView History
As you’ve seen, it’s easy to get current data from RTView. REST queries for history will necessarily be more complex, as we have to include parameters to specify an index for a specific object (e.g., host, EMS queue, database, etc.) and a time range. Hence, we’ll package all the steps in a re-usable R function. The following getHistory function can be pasted into your choice of text editor, and then stored as a file (“getHistory.R”) in your current R working directory. Use the source function as follows to bring the file into your R execution environment.
> source("getHistory.R")
# getHistory queries the RTView REST interface for history data.
#
# By default, this function pulls 24 hours of pendingMessageCount
# data for a given day from the EmsQueueTotalsByServer cache, which
# is indexed by URL of the Tibco EMS server. As seen in the function
# declaration, the query parms (columns, cache, fcol, and time range tr)
# can be overridden to retrieve data from other caches.
#
# Example:
# # retrieve history data for the EMS server indexed in the cache by
# # URL "tcp://192.168.1.116:7222" on the sixth data prior to "today"
# h6 <- getHistory("192.168.1.101","tcp://192.168.1.116:7222",6)
#
getHistory <- function(rtvServer, fval, dayOffset, tz_offset=8,
columns="time_stamp;pendingMessageCount",
cache="emsmon_rtvquery2/cache/EmsQueueTotalsByServer/history",
fmt="text", fcol="URL", tr=86400) {
# set up the base URL for the REST query
base_url <- sprintf("http://%s/%s?fmt=%s&cols=%s&sqlex=true",rtvServer,cache,fmt,columns)
# create a column filter to retrieve rows for a specified index value
emsFilter <- sprintf("fcol=%s&fval=%s",fcol,fval)
# calculate begin time in seconds since 1970
tb <- (unclass(Sys.Date()) - dayOffset)*86400 + tz_offset*3600
timeFilter <- sprintf("tr=%s&tb=%s000",tr,tb)
url <- paste(base_url,emsFilter,timeFilter,sep="&")
#print(url) # debug
read.delim(url) # execute REST query; returns an R dataframe
}
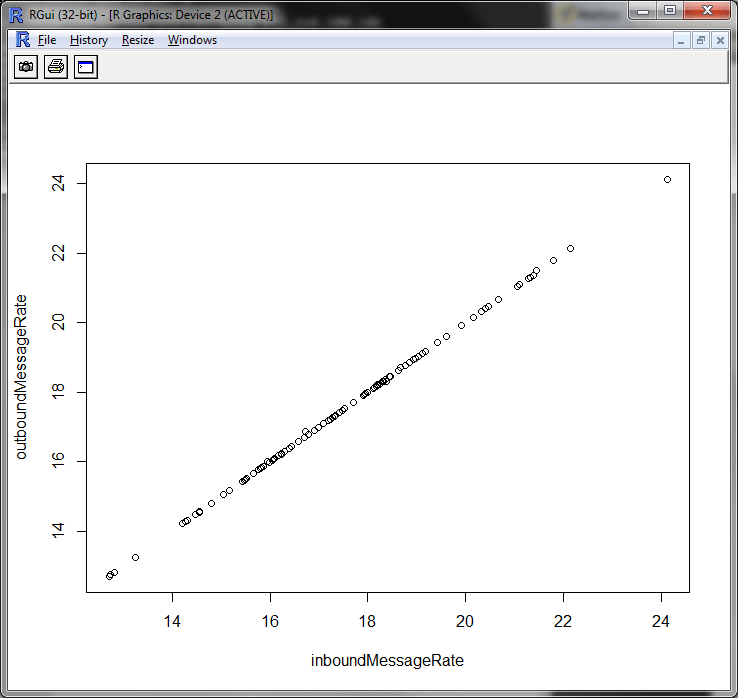
This function is designed for ease of use from the command line. Note that a number of arguments have default values that are appropriate for later modelling efforts, so normally we won’t have to enter them. Let’s do a quick test of getHistory. Here we retrieve data for the inbound and outbound message rates for our EMS server two days ago. Given that consumers are not falling behind, we might expect a linear relationship between these metrics. We’ll confirm this with a scatter plot.
> h <- getHistory("192.168.1.101","tcp://192.168.1.116:7222",2, columns="inboundMessageRate;outboundMessageRate")
> head(h)
inboundMessageRate outboundMessageRate
1 24.125 24.125
2 20.666666666666668 20.666666666666668
3 16.3 16.3
4 18.461111111111112 18.461111111111112
5 19.599999999999998 19.599999999999998
6 19.91111111111111 19.91111111111111
> plot(h)
>
Calculating Bollinger Bands
Customers occasionally ask SL if it is possible to compute and display upper and lower bounds for a given metric. The classic example is “Bollinger Band” plots, where the upper and lower bounds are plotted as the moving average for the metric plus or minus a standard deviation. A related question is, given such a plot, is it possible to generate alerts when the real-time trend crosses a boundary, which is generally interpreted as over-bought or over-sold in the context of stock trades. The answer to both questions is “Yes!” Although the calculations can be done by RTView, we will show them in R. The task of importing the results into RTView for display and alert generation will be explored in a future application note.
As a use case for this exercise, the goal will be to calculate an upper and lower bound for total pending messages queued by a TIBCO EMS server over the next 24 hours using Bollinger’s method. The messages are related to online customer orders, so as the volume increases, the total wait time in the queue per message increases, resulting in degraded customer experience scores. We’ll assume that the customer has developed a sophisticated model for predicting the expected sales profile for the next business day, which takes into account holidays and other business considerations. There are a number of options for computing the rolling average. Let’s say it is an ordinary Monday and nothing special is happening tomorrow. In this case, the model simply averages the trends for the previous two Tuesdays, and then computes a rolling average and standard deviation. First, we call getHistory with different day offsets to get data for the two previous Tuesdays (6 and 13 days ago).
> h6 <- getHistory("192.168.1.101","tcp://192.168.1.116:7222",6)
> h13 <- getHistory("192.168.1.101","tcp://192.168.1.116:7222",13)
The following R code implements our model for computing Bollinger Bands.
#########################
#
# movingAvg calculates a moving average for the input vector x
# using a window of size "n" (default 5).
#
movingAvg <- function(x,n=5){filter(x,rep(1/n,n), sides=1)}
#########################
#
# modelData executes a simple model to predict the behavior of a
# given metric over the next 24 hours.
#
# Given two time series of samples for a given metric on two days,
# this function averages the two series, smoothes the result with a
# moving average (default window is 8 samples). The Standard Deviation
# is then added and subtracted to the moving average to create the
# upper and lower bounds for a Bollinger Band. The results are plotted
# and optionally saved as a pdf file.
#
modelData <- function(day1, day2, ma_window=8, savePDF=F, modelFile="model.pdf") {
if(savePDF) pdf(modelFile) # optionally open a file to store the pdf
# average the two days of data, smooth the result with a moving average,
# and then remove any "NA's" introduced by the moving average.
mavgDay <- na.omit(movingAvg((day1+day2)/2))
par(mfrow=c(2,1)) # plot two charts; first chart is raw input + smoothed trend
plot(day1,xlab="Time",ylab="pending messages",main="Days -6 and -13, Moving Avg")
points(day2,col=2,pch=2) # overlay data for second day
lines(mavgDay,col=3) # overlay the smoothed moving average
# create Bollinger bounds by biasing the smoothed average up and down
# by one standard deviation.
sdDay <- sd(mavgDay)
upperBound <- mavgDay + sdDay
lowerBound <- mavgDay - sdDay
# plot the Bollinger Band
plot(upperBound, ylab="pending messages", main="Bollinger Band", ylim=c(min(lowerBound),max(upperBound)))
lines(lowerBound,col=3)
if(savePDF) dev.off() # close the pdf file.
cbind(upperBound,lowerBound) # return the Bollinger bounds
}
We’ll call this model interactively from the R command line and adjust the level of smoothing until the trend becomes clear and we’re satisfied with the results. Each call to modelData generates two plots like those shown below.
> modelData(h6$pendingMessageCount,h13$pendingMessageCount) # defaults to 8 samples
> modelData(h6$pendingMessageCount,h13$pendingMessageCount,15)
> modelData(h6$pendingMessageCount,h13$pendingMessageCount,20)
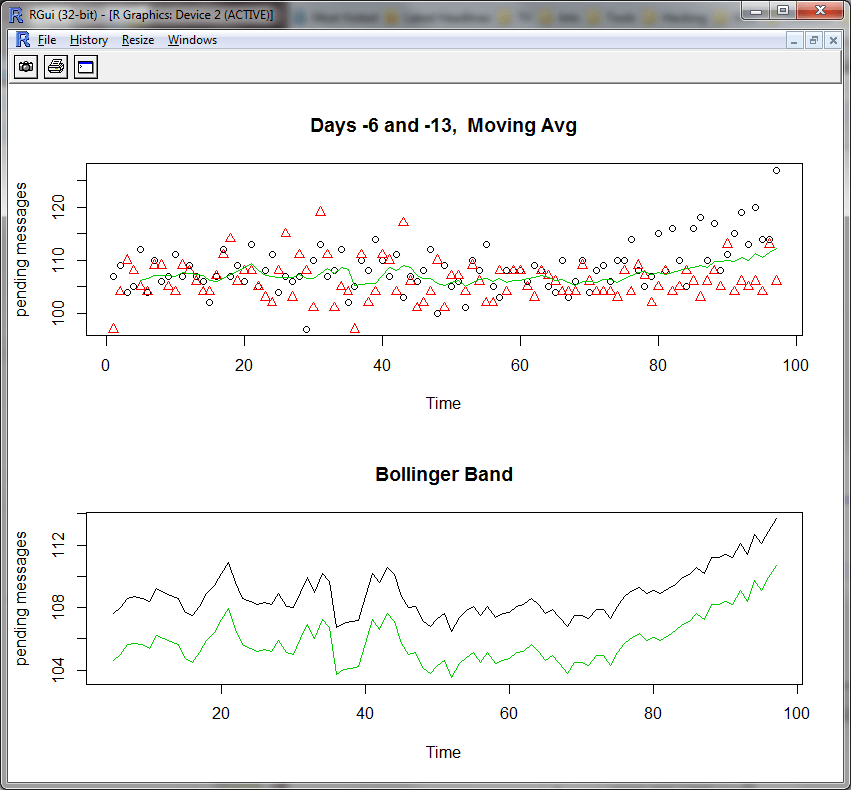
Note that the pending message data is rather noisy, so setting the bands at plus or minus one standard deviation as calculated from the smoothed data might not work very well in practice, but that’s part of the “art” of modelling!
If you examine the RTView history data in your interactive shell, you may notice that modelData works with two input vectors of pending message data at 15 minute resolution. The sample times are stripped in the call to modelData, and so the plots show relative time in terms of sample index. Although R has extensive support for time series data, to keep things simple those features are not used here. If there are missing data samples in either vector, the time sequencing for samples in the two arrays would be out of sync, and the averaging step (day1+day2)/2 could either fail or silently compute a nonsensical result. Finally, the rolling average tends to shorten the result vector, so we need to pull slightly more than 24 hours of data to ensure we calculate a result that covers the entire day. Hence, there’s more work to do to make this code “production quality”.
Conclusion
Hopefully, this article has shown you that R is a powerful environment for exploring your RTView data. The previous section indicated areas in which additional research and development could further simplify analysis. Other areas include scheduled tasks run using rscript, and the ability of rscripted applications to push data to RTView Enterprise Monitor via the agent interface. Hence, SL is actively exploring tools that could be bundled in an R package for use by customers. If you have challenging requirements that could be satisfied by this effort, we invite you to contact us and collaborate on this exciting new development.
Visit the SL Corporation web site, www.sl.com, to learn more about what RTView can do for you.
Tags: R
Categories: Developer's Corner